What is a LakeHouse?
A Lakehouse is a data management architecture that is a combination of both data lakes and data warehouses. Before we jump into the definition of Lakehouse it is important to better understand the difference between Datalake and DataWarehouse individually. A Lakehouse allows you to use both the Datalake and DataWarehouse together which lets you manage and analyze the data from different frameworks and tools. The idea is to reap the benefits of both by storing huge amounts of diverse data from Datalake along with providing a reliable, consistent, and efficient query performance of a DataWarehouse. In other words, a Lakehouse combines the best of both worlds allowing organizations to store raw data in a lake-like fashion while also providing structured, queryable data similar to a traditional warehouse.
| Datalake | DataWarehouse | |
| Purpose | Serves as a repo of raw data of various formats | Serves as a centralized repo for storing, integrating, and analyzing structured data, caters for the data needs of an organization as well |
| Advantages | Suitable for handling data from diverse sources | Made for handling structured data |
| Cost-effective due to reducing the cost of cloud storage | Can handle huge amounts of data at the same time maintain versioning and logs | |
| Limitations | No data quality is enforced | Cannot handle unstructured/semi-structured data (modern DWH can provide a mechanism to handle semi-structured data) |
| Inconsistent and makes it hard to handle reads, batch and stream jobs combination | Not cost-efficient | |
| Transaction support is limited |
Now that we know the difference between a Datalake, DataWarehouse, and a DatalakeHouse, let’s see how we can create our first Lakehouse and convert the datalake files into DataLakehouse tables in Microsoft Fabric.
Creating a LakeHouse:
Things that we need for this exercise:
- Fabric trial account
- New workspace
Login into the Fabric landing screen dashboard
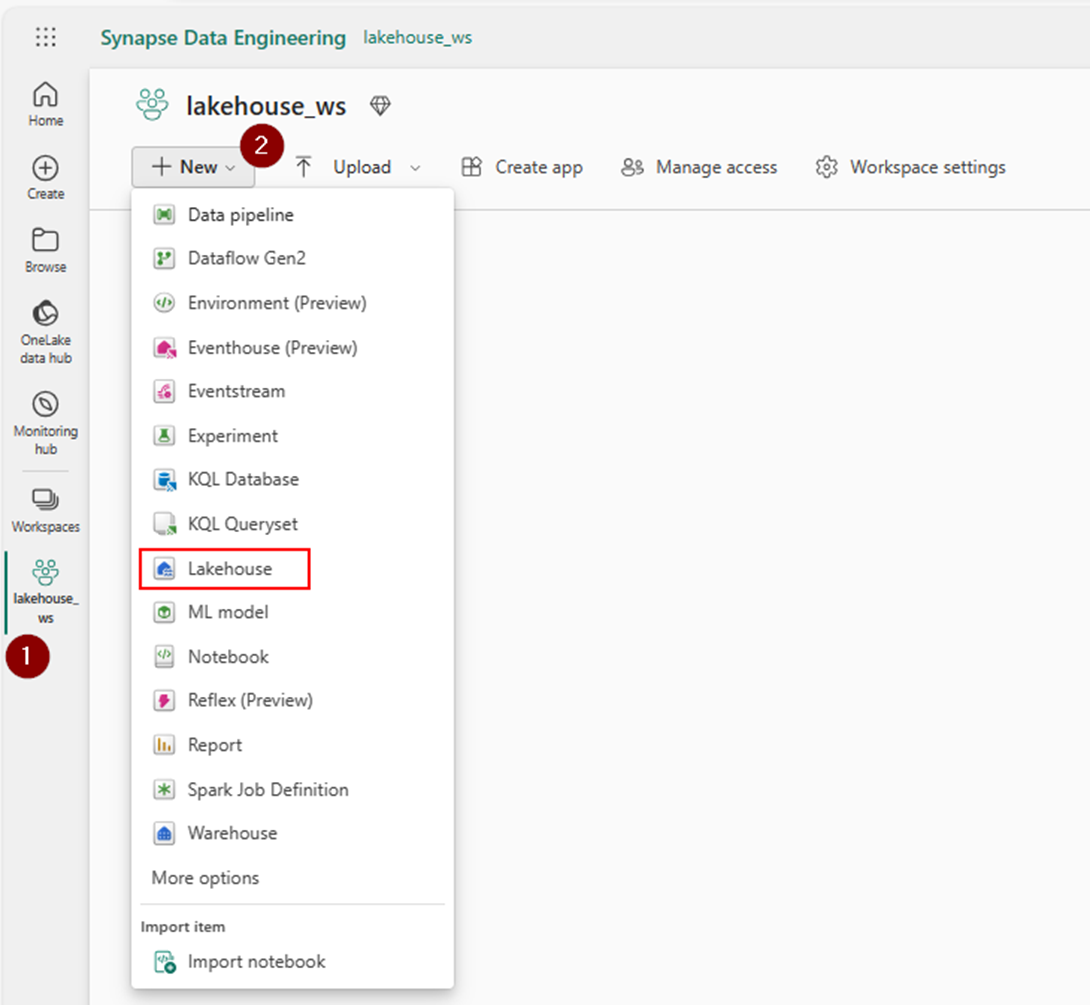
A warehouse will automatically be created in the background when you create a lakehouse in fabric. Each workspace can have more than one lakehouse and each will have its SQL endpoint. The number of endpoints in a workspace matches the number of lakehouse items. SQL endpoints will let you access the data present in the them directly using traditional t-sql queries. In addition to this, you can treat it like a full-blown DataWarehouse database under which you can create views and even set sql policies.
Getting your data into the lakehouse:
There are multiple ways through which you can take your data into the Lakehouse.
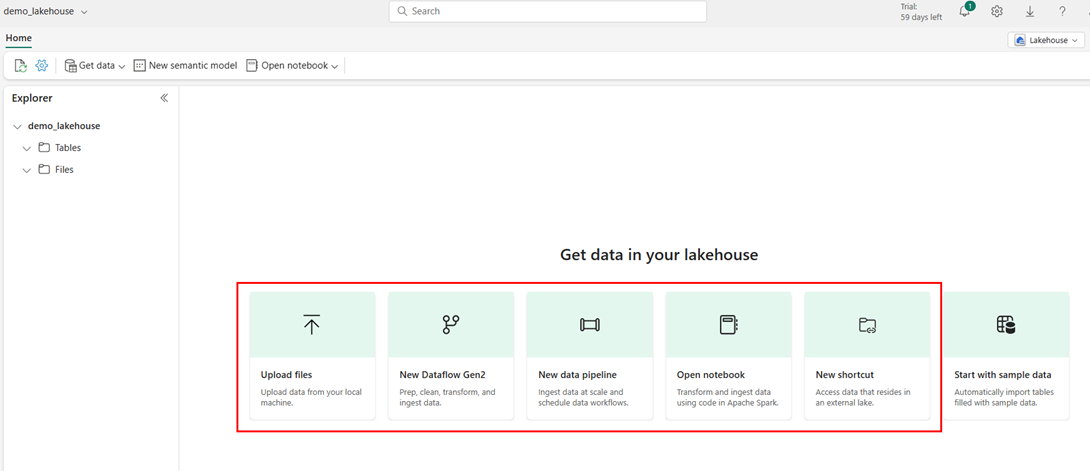
For this demo, I will select the 3rd option, ‘New data pipeline’ and under it, the ‘Copy Data’ activity to bring my data into the lakehouse. Once you are here, you will get all the options like multiple types of Data source and destination connectors and some sample datasets for import. I am selecting ADLSGen2 as my source since I have my fileFor this demo, I will select the 3rd option, ‘New data pipeline’ and under it, the ‘Copy Data’ activity to bring my data into the lakehouse. Once you are here, you will get all the options like multiple types of Data source and destination connectors and some sample datasets for import. I am selecting ADLSGen2 as my source since I have my files there.
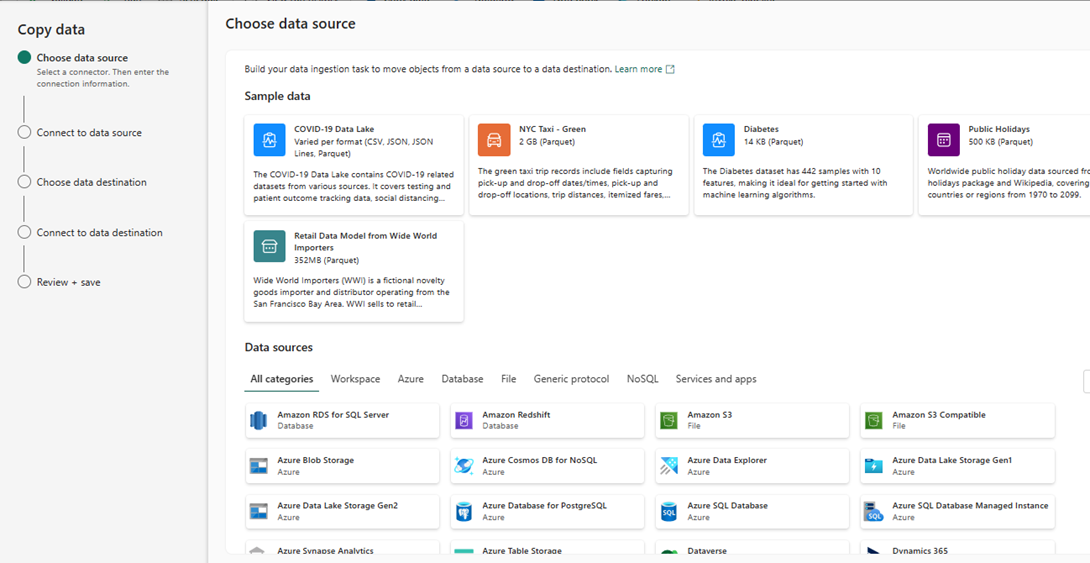
While creating a new connection you will have the option to authenticate the storage account with SAS Key, Storage account, Service principal or Organizational Account, you can choose any option that would suit your scenario. I am connecting using the ‘Organizational account’ option since I have both my Fabric and ADLSGen2 in the same subscription.
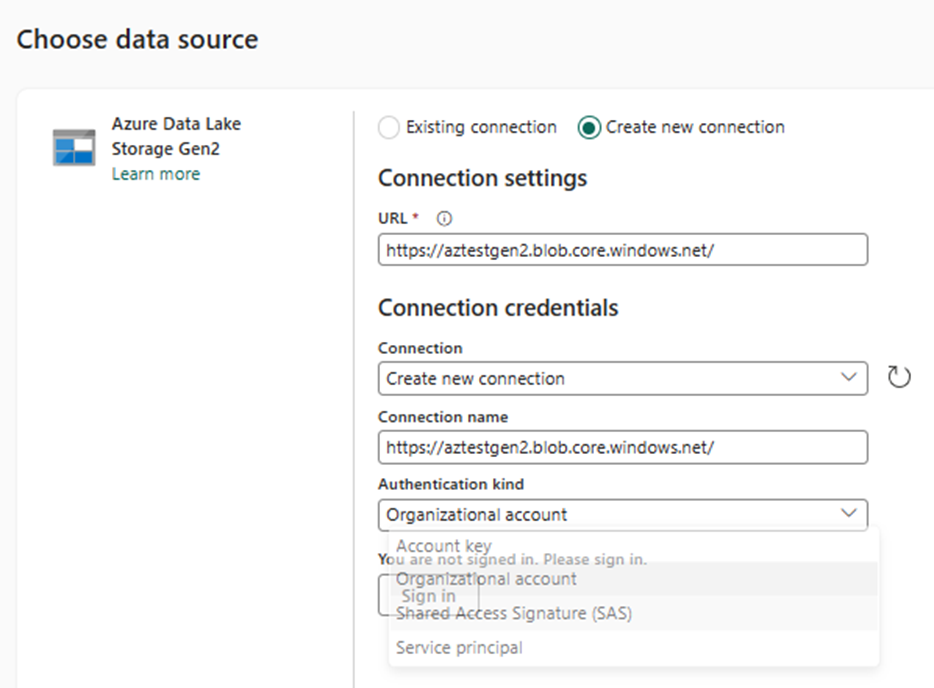
Once you have created the connection, the copy tool asks whether you want to copy the parent or sub-folder from the source location. I am choosing the sub-folder called ‘Fin_files’ so that it can pick all the files under it.
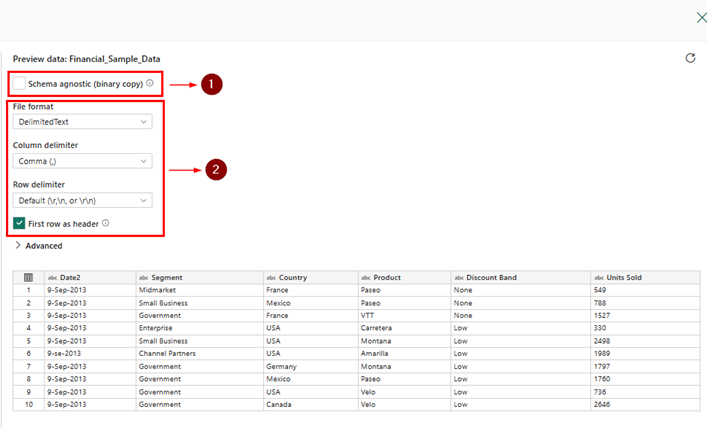
There are two ways to launch the data.
- Land the data as a binary copy using the ‘Schema agnostic (binary copy)’ option as is in the source. With this option,
- Files will be treated as binaries
- Schema cannot be enforced
- The destination cannot be a relational database
- Landing the data in a structured format in delta format
- Will try to read the data format and treat it accordingly
- Has multiple File Format options
Since my sample data is in CSV format, it detects the file type and hence provides the column and row delimiter options, but for this demo, I am going with the ‘Schema agnostic’ (Files) option.
Then at the next level, I select ‘LakeHouse’ as my data destination. Remember that I have already created a LakeHouse initially which I am going to use now.
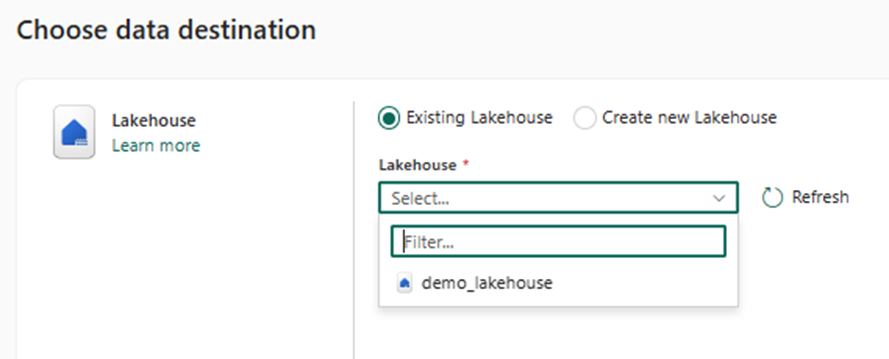
I am not specifying any specific folder destination (leaving it to be in the parent folder itself) or copy behavior as any conditions, hence leaving it as default in the next screen.
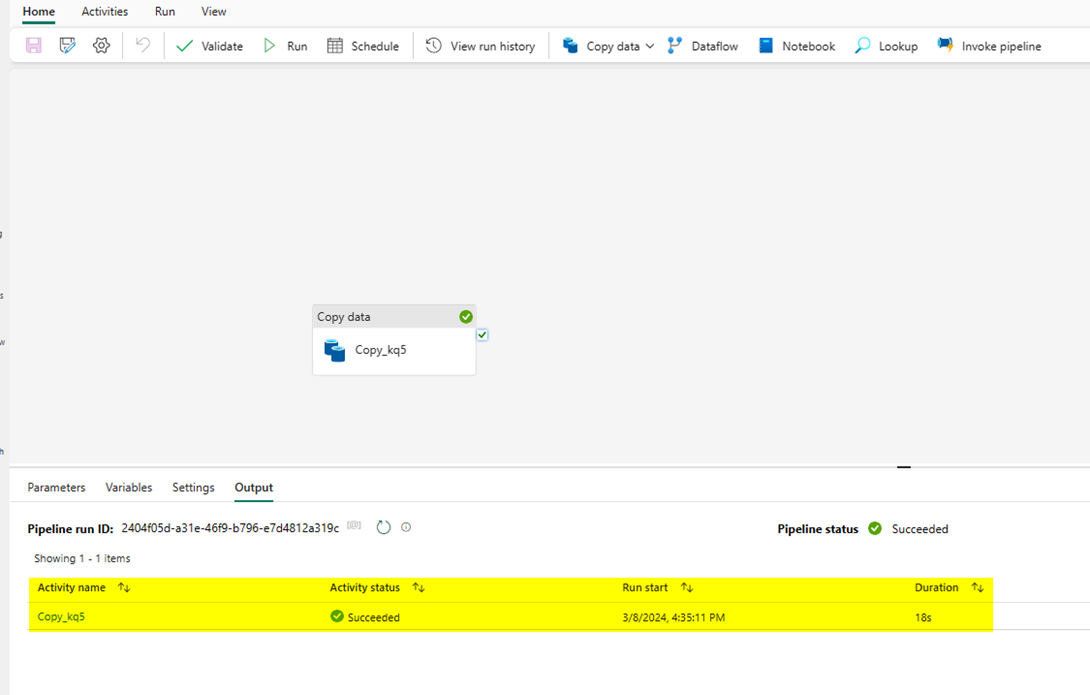
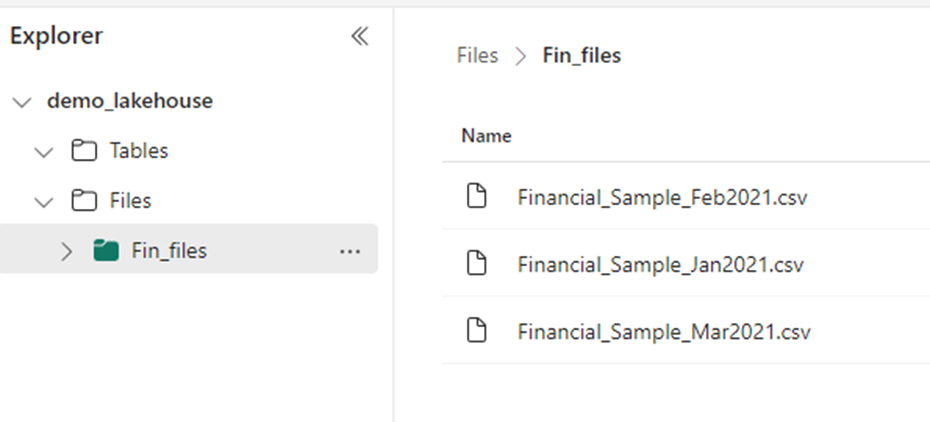
Once the pipeline has been completed successfully, you can now see the files in the LakeHouse under the ‘Files’ section.
Now there are two options to convert these Datalake files into LakeHouse tables based on our convenience:
Option 01: No-code solution using LakeHouse Explorer UI in the Fabric portal
Option 02: Notebook using Spark code
Option 01:
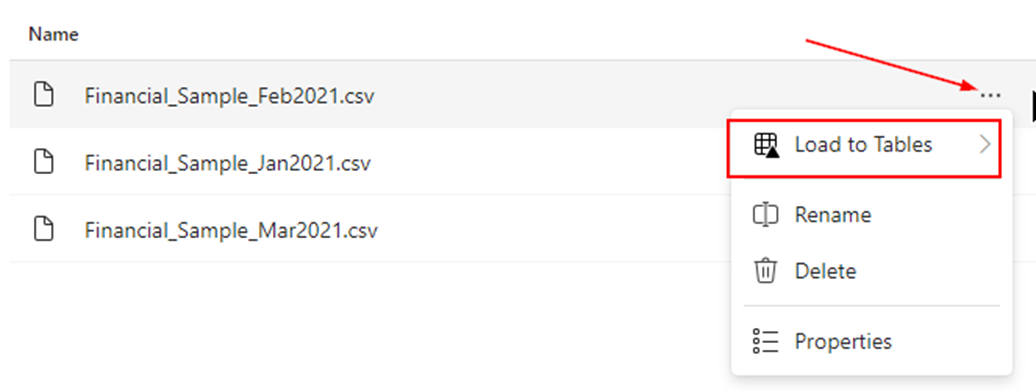
If you want to load any file into a LakeHouse table, you can simply click on the ellipses button followed by the ‘Load to Tables’ option.
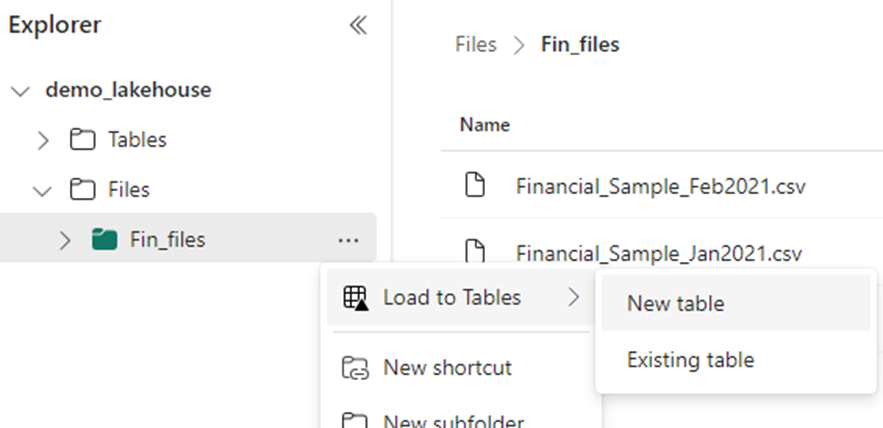
Or if you want to load all the files from the folder into the table since all of them belong to the same data, you can load them directly from the subfolder.
You can see the entire files from the subfolder have been appended into a single table.

Option 02:
Copy the ABFS path: this returns the absolute path of the file which we will use in our spark code.
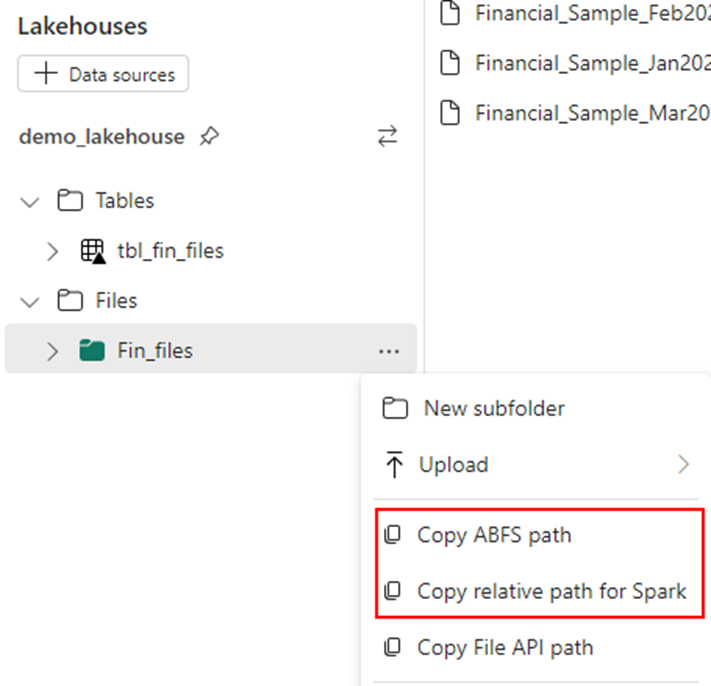
Using spark code, I am loading all the files in the subfolder first into a dataframe
df=spark.read.csv("abfss://lakehouse_workspace@onelake.dfs.fabric.microsoft.com/demo_lakehouse.Lakehouse/Files/Fin_files", header=True)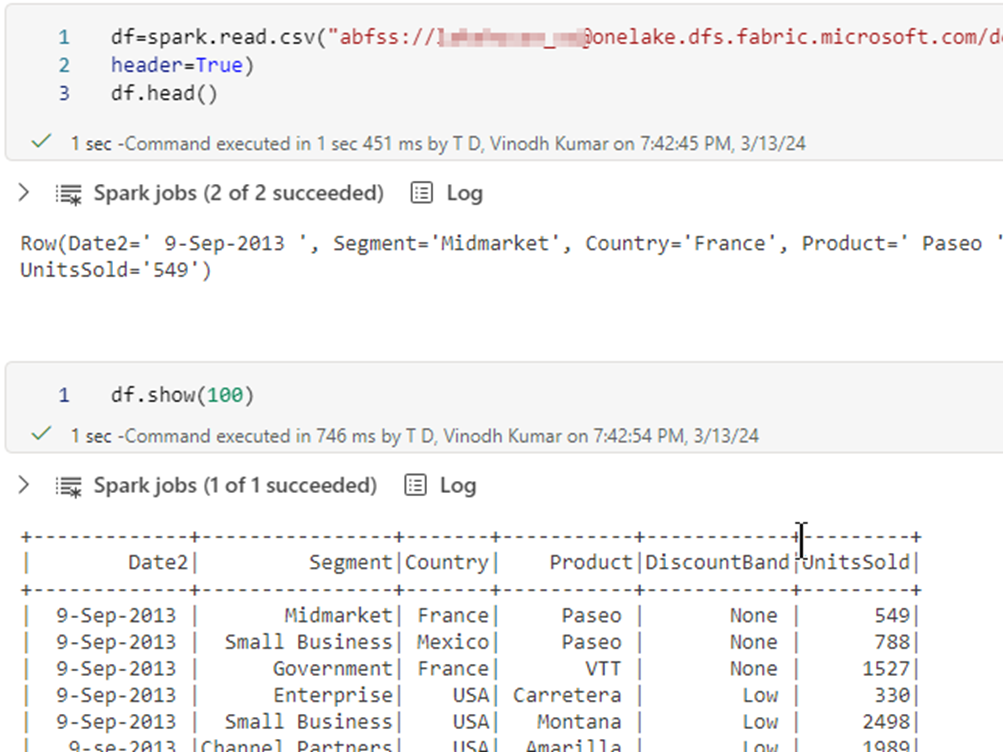
Once into the dataframe, I am writing into a new table in delta format. You can also append into an existing delta table by changing the mode from ”overwrite” to “append”.
df.write.mode("overwrite").format("delta").saveAsTable("notebook_tbl_fin_files")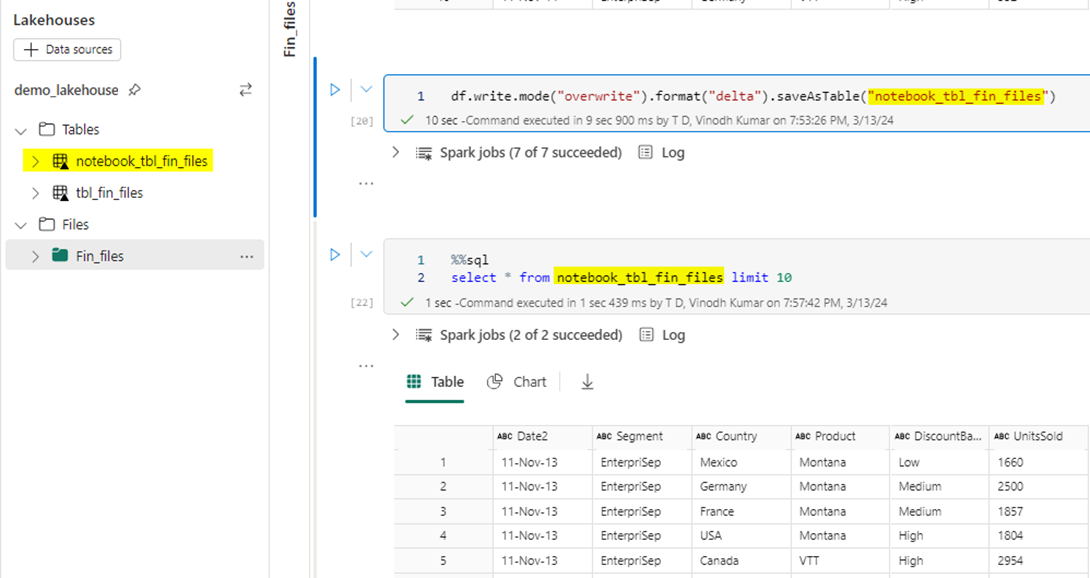
You can also load through Pandas API which is not discussed here.