Introduction:
In this post we will discuss on how to create an external table and to store the data inside your specified azure storage parallelly using TSQL statements.
What is CETAS:
CETAS or ‘Create External Table as Select’ can be used with both Dedicated SQL Pool and Serverless SQL Pool to create an external table and parallelly export the results using SQL statement to Hadoop, Azure storage blob or Azure Data Lake Storage Gen2. The data will be stored inside a folder path within the storage which has to be specified. Some of the important elements of CETAS are External Data Source and External File Format and I have written in detail about External data source in my previous article.
I am going to use the same logical database that I created in my previous exercise when creating external datasource and the sample data we will be using is ‘NycTaxi.parquet’ file which I have already uploaded in the data lake storage. Below are the complete steps including the TSQL statements, please refer my previous article for detailed explanation on steps 1 & 2.
Step:1 – Creating Database scoped Credential
CREATE DATABASE SCOPED CREDENTIAL [ADLS_credential]
WITH IDENTITY='SHARED ACCESS SIGNATURE',
SECRET = 'sv=XXXXXxxxxxxxxxxxxxxxxxxx'
GO
Step:2 – Creating External Data Source
CREATE EXTERNAL DATA SOURCE demo
WITH ( LOCATION = 'https://synadlsgen2.blob.core.windows.net/output',
CREDENTIAL=[ADLS_credential])
Step:3 – Creating External File Format
External file format defines the format of the external data that you are going to access. It will specify the layout of the type of data that is going to be referenced by the external table. In azure synapse currently only two file formats are supported
- Delimited Text
- Parquet
I have used the second one since the demo file NycTaxi we are going to use is parquet file format. Default snappycodec compression option has been used for this.
CREATE EXTERNAL FILE FORMAT ParquetFileFormat
WITH (
FORMAT_TYPE = PARQUET,
DATA_COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
)
Step:4 – Creating Schema
The next step is creating the schema as all the external table and other database objects will be contained within the Schema.
CREATE SCHEMA nyctaxiStep:5 – Creating External Table
It is now time to create the external table which is the objective of this demo. Given below is the query which creates external table and the select statement from which it pulls the data from the parquet file. Now it all looks good, lets run it.
You can see that the select statement has been included when creating the external table as I am loading the aggregated results from the select statement directly onto the table.
CREATE EXTERNAL TABLE nycdemotable
WITH (
LOCATION = 'synadlsgen2/output',
DATA_SOURCE = demo,
FILE_FORMAT = ParquetFileFormat
)
AS
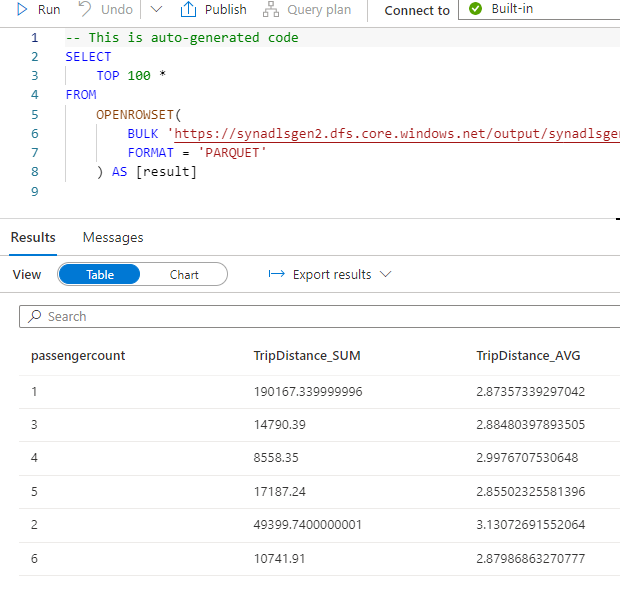
SELECT passengercount, sum(tripdistancemiles) as TripDistance_SUM, avg(tripdistancemiles) as TripDistance_AVG
FROM
OPENROWSET(BULK 'https://synadlsgen2.blob.core.windows.net/adlsfssyn/NYCTripSmall.parquet',
FORMAT='PARQUET') AS [rows]
WHERE tripdistancemiles>0 AND passengercount>0
GROUP BY passengercount
GO
I have run the select query alone to verify the table count and output and if the parquet available in ADLS is accessible.
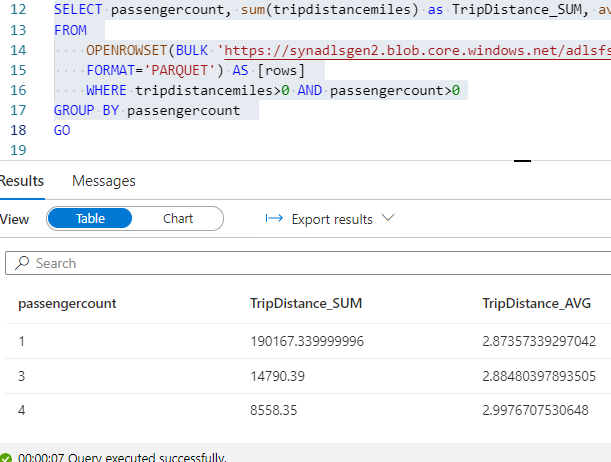
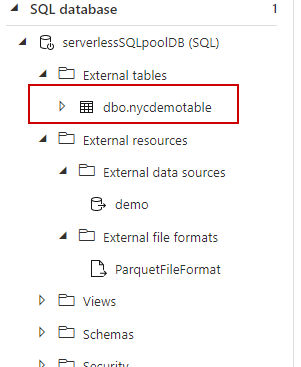
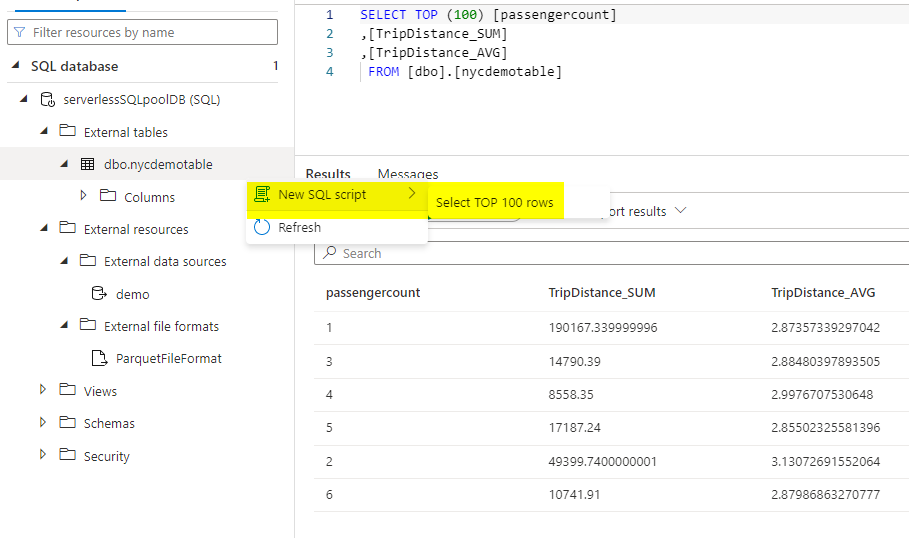
We could see the external table is now created. Right click and select top 100 rows to see the results.
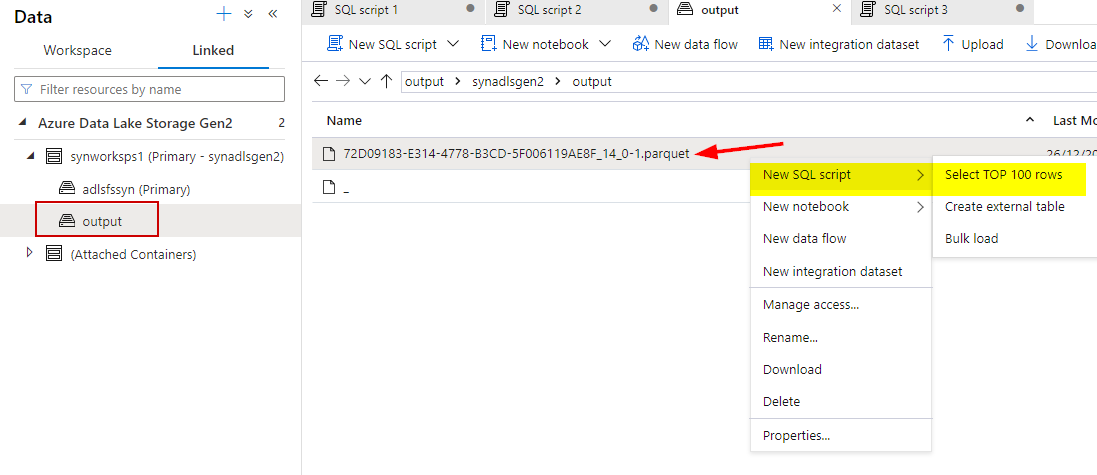
Now go to the ADLS storage to check if the output from select has been saved into file format as well.
This explains what is CETAS in synapse and how could we utilize it for parallel processing on different file formats. More practical scenarios will be posted in upcoming articles.